Qwen3 Mid-Tier AI Model Delivers Hybrid Reasoning Power with Unmatched Efficiency

Qwen3 Advances Mid-Tier AI Model with Hybrid Reasoning and Efficient Performance
The latest iteration in the Qwen model family brings notable enhancements to its mid-sized offering, introducing a refined architecture that balances scale and operational efficiency. This new release features a sophisticated parameter management system, activating only a fraction of its 30 billion parameters at any given moment while maintaining performance that rivals prominent contemporaries in the space. This sophisticated balance marks a significant milestone in optimizing AI capabilities without the traditionally immense resource demands.
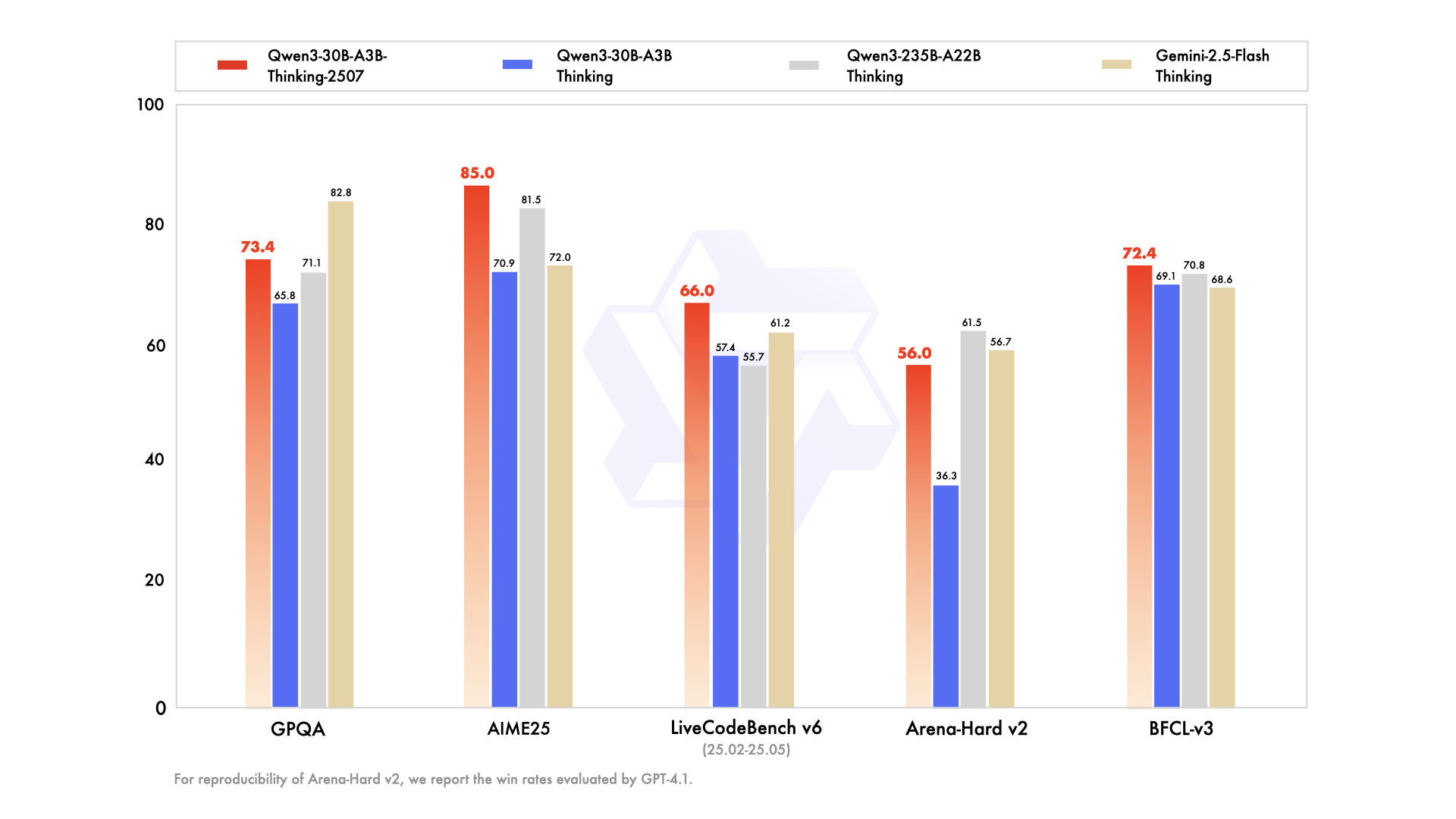
In development circles, this model has demonstrated robust performance across demanding scientific benchmarks, programming tasks, and agentic behavior evaluations. Impressively, it achieves results that meet or surpass those of much larger counterparts. The ability to deliver such outcomes, even with a trimmed active parameter set, showcases an evolution in model engineering, where intelligent design trumps mere size.
While the computational intensity remains a consideration—requiring substantial hardware infrastructure—the architecture theoretically supports local deployment. This opens avenues for private, high-powered AI functionalities without exclusive reliance on cloud-based services. The model is currently accessible for online experimentation, providing developers and users with immediate opportunities to engage with its capabilities firsthand.
Architecture and Parameter Efficiency
This generation employs a mixture-of-experts (MoE) design, which dynamically activates only a subset of the full parameter set during inference. By triggering approximately three billion parameters out of its 30 billion total, the system significantly lowers the computational burden. This approach enables efficient resource utilization, shifting the paradigm from monolithic large models towards adaptable architectures that can toggle their reasoning depth depending on task demands.
This selective activation is complemented by a hybrid reasoning mechanism allowing dual operational modes. Users can switch seamlessly between rapid-response mode and an in-depth, chain-of-thought reasoning mode. The former suits workflows needing swift outputs, while the latter provides comprehensive, considered answers suitable for complex problem-solving scenarios. This functionality is particularly impactful for tasks demanding logical rigor or multi-step inference, such as mathematical reasoning or software code synthesis.
Benchmarking and Comparisons
Early evaluations place this mid-tier release on a competitive footing with other advanced models including Gemini 2.5 and OpenAI’s recent open models with similarly scaled architectures. Specific assessment domains include scientific reasoning challenges, coding proficiency tasks, and agentic evaluations that measure autonomous decision-making capabilities. Notably, the model matches or exceeds performance levels typically associated with larger models, which traditionally required more memory and processing power.
The results highlight that parameter quantity alone is not the sole determinant of intelligence or task proficiency in language models. Instead, architectural nuance, adaptive resource management, and thoughtful pretraining datasets contribute heavily to overall effectiveness. This updated architecture demonstrates how careful engineering yields substantial performance benefits even at mid-range scales.
Deployment and Accessibility
Operational requirements remain significant, as the architecture’s complexity demands formidable computational resources. However, the design’s theoretical support for local execution presents a key advantage for privacy-conscious or latency-sensitive applications. Running such models on-premises avoids dependency on intermittent internet connectivity and mitigates data exposure risks linked with cloud processing.
Importantly, the model is already available for interactive use via an online chatbot interface, inviting developers, researchers, and enthusiasts to test its abilities without immediate infrastructure investment. This accessible entry point accelerates adoption and real-world validation, encouraging community-driven exploration and feedback.
Market Implications and Competitive Landscape
This update arrives at a critical juncture in large language model development. As several open models emerge globally, this refined mid-tier solution challenges others to elevate their design strategies, particularly in balancing performance with operational efficiency. The new model’s ability to effectively conserve computation while delivering on complex tasks exemplifies a shift toward smarter, not just bigger, AI.
The presence of such capable mid-range options enriches the ecosystem by offering scalable solutions suitable for a variety of applications—from enterprise integrating targeted AI assistants to developers requiring versatile coding companions. It places competitive pressure on contemporaries, prompting continuous innovation in model architectures and deployment strategies.
Conclusion
The latest enhancement within this AI series exemplifies a sophisticated evolution from traditional monolithic designs toward modular, resource-conscious architectures. By activating a relatively small portion of its vast parameter base at any given moment, it achieves a remarkable balance between computational efficiency and task performance. Its strong results across scientific benchmarks and programming challenges underscore the effectiveness of this approach.
The capacity for local operation further distinguishes this offering, broadening its practical applicability and catering to a range of user preferences and operational constraints. As this solution gains traction, it may set new expectations for mid-sized models' capabilities, influencing the direction of future AI model development across the industry.
With this advancement, companies developing large open models may need to reassess their strategies to maintain competitive parity. The introduction of such resource-efficient, high-performance models marks a significant turning point in the AI development landscape.