DeepSeek-V3.2 Delivers Breakthrough Efficiency and Cost Savings for Neural Language Models

DeepSeek-V3.2 Unveiled: Game-Changing Efficiency in Neural Language Models
The Next Leap for Large Language Models from China
A surge of excitement surrounds the debut of a breakthrough in artificial intelligence: DeepSeek-V3.2. This experimental neural network, designed by a rising technology firm in China, marks a critical progression from its predecessor. By integrating a specialized sparse attention mechanism, this innovation aims to reshape cost, scalability, and performance standards in the world of large language models.
At its core, DeepSeek-V3.2 is built to accommodate exceptionally long input contexts without compromising cognitive abilities or answer quality. This is achieved by optimizing how attention is distributed across sequences, resulting in a model that can process lengthy or complex inputs more rapidly and with improved resource allocation. This aspect is crucial for real-world applications including advanced natural language processing, generative AI tools, and expansive conversational agents.
The shift to sparse attention—where computational focus narrows to only the most relevant segments of an input—means DeepSeek-V3.2 can manage higher efficiency even as context windows scale up. This design emerges as an attractive proposition for organizations seeking to leverage high-capacity AI without incurring prohibitive infrastructure costs.
Performance Benchmarks, Context Handling, and Reasoning
Benchmarks indicate the upgraded variant holds its ground across standard metrics for language intelligence and comprehension. While certain tests that measure “depth of reasoning” register slight dips in performance, evaluators and developers emphasize a significant detail: The difference results from the model’s tendency to deliver more concise, efficient answers. In scenarios where responses contain an equivalent volume of informative content, performance parity is quickly restored.
This optimization is particularly relevant in tasks requiring extensive analysis or multi-turn dialogue. By ensuring the system can maintain accuracy even as context size grows, DeepSeek-V3.2 appeals to sectors demanding large-scale document understanding, contextual search within massive databases, or real-time content moderation.
The innovation also shines in its ability to balance expert load during training, employing architectural mechanisms to prevent any single computational component from becoming overwhelmed. This maintains both rigorous consistency and robustness across use-cases—vital for enterprise-scale AI deployments and research applications alike.
Rewriting the Economics of AI: Cost Reduction and Open Access
Perhaps the most transformative aspect of DeepSeek-V3.2 is its pricing. By slashing costs for both input and output token processing by half or more compared to the previous generation, the model positions itself at the frontier of accessible high-performance AI. For developers and organizations grappling with the expense of leveraging state-of-the-art language models, this systematic price drop dramatically expands the feasibility of integrating AI into numerous workflows.
This shift unlocks new possibilities: Content platforms, chatbot services, document analysis firms, and countless SaaS providers now encounter a distinctly lower barrier to entry for embedding advanced generative AI. As artificial intelligence deployments move from lab experiments to mission-critical infrastructure, this pricing overhaul is more than incremental—it plays a fundamental role in AI adoption rates and market expansion.
Furthermore, open availability through public-facing channels empowers independent researchers, startups, and students to engage with advanced neural models, fostering broader innovation and experimentation. Access to a well-documented, robust model capable of handling significant context at low operational cost serves as a catalyst for fresh applications and business models.
Technical Innovations: Architecture and Versatility
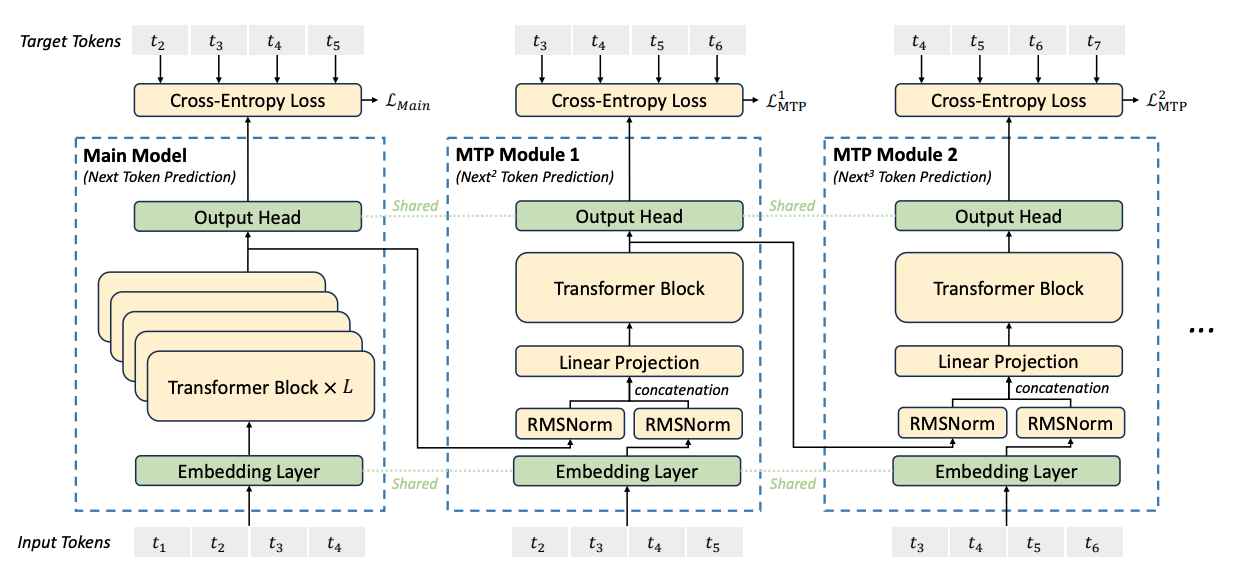
The model’s backbone is a sophisticated mixture-of-experts framework, enabling computational efficiency on a scale rarely witnessed in open-access AI. DeepSeek-V3.2 integrates multi-token prediction during training to refine comprehension and response capabilities. Underlying training strategies leverage mixed-precision arithmetic, further boosting computational speed while curbing resource consumption.
Advanced architectural choices—such as dynamic gating for routing tasks to specialized expert networks and innovations to prevent computational bottlenecks—set this neural engine apart. These features contribute to both the model’s adaptability in multitasking environments and its reliability for long-term deployment.
Emphasis on modularity ensures that elements of this ecosystem are easily reconfigured for tailored implementations, supporting custom integrations in diverse industry verticals. From clinical documentation to legal case analysis, the flexibility of this AI is poised to create measurable impacts wherever contextual understanding and speed are at a premium.
Conclusion: What DeepSeek-V3.2 Means for the AI Landscape
The arrival of DeepSeek-V3.2 signals a pivotal moment for neural language models and underscores the rapid advancement of AI capabilities from China’s tech sector. As organizations seek AI solutions that blend cost-efficiency, scalability, and state-of-the-art performance, this model offers a compelling option for those aiming to stay ahead in natural language processing, document automation, and intelligent communication.
With ongoing support and open channels for community feedback, DeepSeek-V3.2 is set to influence both the trajectory of AI research and its day-to-day application across business, science, and public domains. Its combination of sparse attention architecture, context-aware efficiency, and sharply reduced pricing heralds a new chapter for enterprise AI and beyond.